TL;DR — llama-nemotron-embed-vl-1b-v2 is a ~1.7B parameter VLM (SigLip2 vision encoder + Llama 3.2 1B backbone) that handles text, images, and image+text through one forward pass and produces a single 2048-dim vector. The ViT compresses each image tile from 1024 to 256 tokens via pixel-shuffle before fusing into Llama's embedding space via masked_scatter. Two Triton deployment strategies: a single fused TRT engine (simple, but always pays the ViT cost even for text-only requests) and a multi-engine BLS router (more moving parts, but genuinely skips the ViT for text-only traffic and scales each submodel independently).
NVIDIA's llama-nemotron-embed-vl-1b-v2 is a multimodal embedding model that handles text, images, and image+text through the same forward pass and outputs a single 2048-dim vector. It's built for document retrieval over mixed corpora — PDFs, charts, screenshots — where you'd otherwise need separate embedders for each modality. This post is Part 1 of three. Here I'll cover what the model is, how it processes inputs, and the two ways I evaluated for serving it on Triton + TensorRT. Part 2 covers the implementation details, and Part 3 covers the perf_analyzer results.
Table of contents
- What is llama-nemotron-embed-vl-1b-v2?
- The architecture, end to end
- Walking through each stage
- Serving the Model
What is llama-nemotron-embed-vl-1b-v2?
Released by NVIDIA in December 2025, this is an Eagle 2 VLM: a SigLip2-400M vision encoder paired with a Llama-3.2-1B text backbone, clocking in at about 1.7B parameters total. The output is a single dense vector at dim 2048, regardless of whether the input was text, an image, or both. Max context is 10,240 tokens — images are tiled up to six tiles plus a thumbnail, with each tile consuming 256 visual tokens.
The practical appeal is that one model indexes a mixed corpus. Text chunks and page screenshots end up in the same vector space, so you can hit them with the same query at retrieval time.
For the rest of this post, I’ll use simplified shapes to keep the diagrams readable. Everything generalizes to the full envelope:
- one image tile (256 visual tokens)
- sequence length 1024
The architecture, end to end
The pipeline has five stages: vision encoding, text embedding, fusion, the Llama transformer, and pooling. Here's how they connect:
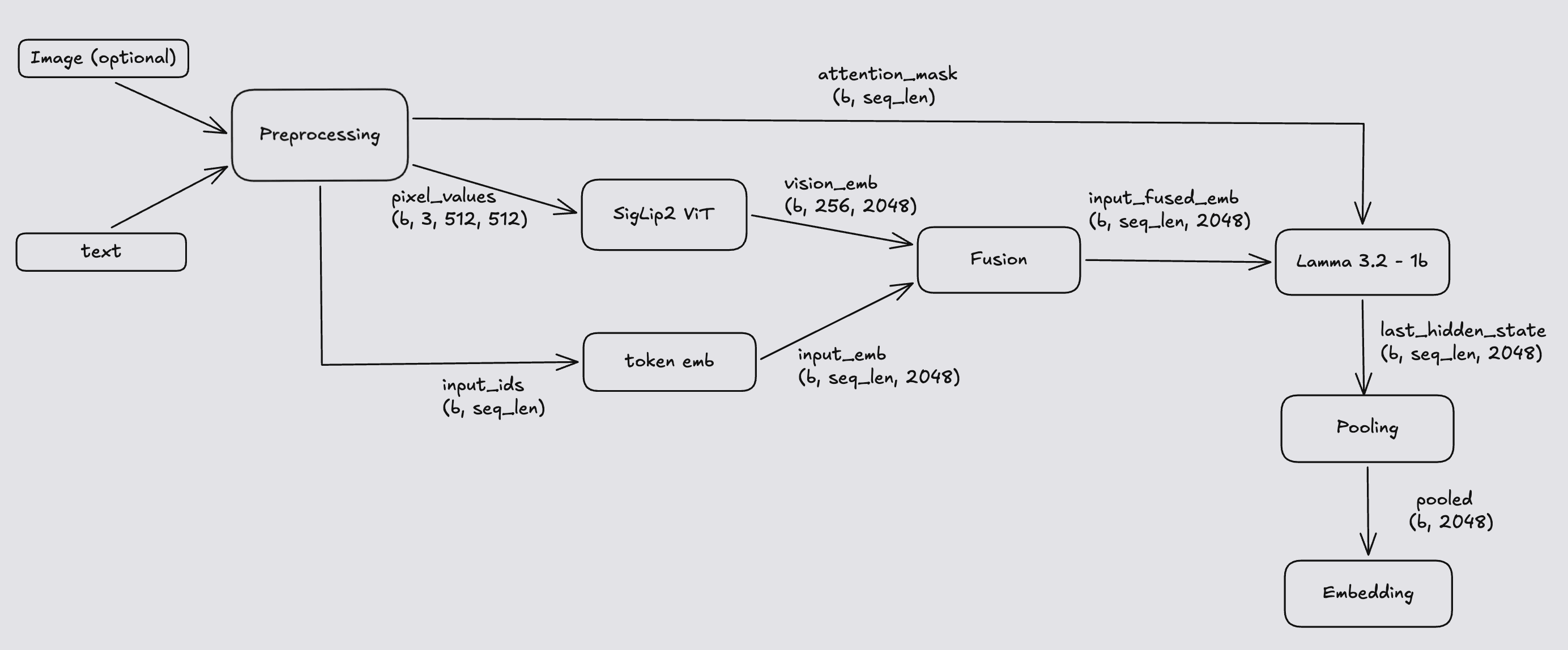
The dashed orange edges are the vision-only path — they carry data only when the request includes an image.
Walking through each stage
Vision encoder (SigLip2)
SigLip2 takes a 512×512 image and produces patch embeddings via a standard ViT. At 16×16 patches, that's 32×32 = 1024 patches, yielding raw output of shape (B, 1024, 1152). With six tiles plus a thumbnail you'd be at roughly 7,168 visual tokens before any text shows up — most of your context budget gone.
Nemotron compresses this in two cheap steps. First, a pixel-shuffle (lossless rearrangement) trades spatial resolution for channels: (B, 1024, 1152) → (B, 256, 4608). No information is dropped; adjacent patches get packed into the channel dimension. Second, a linear projection (mlp1) maps into the LM hidden size: (B, 256, 4608) → (B, 256, 2048). Every tile ends up as 256 vision tokens of dim 2048, dimensionally compatible with Llama's embedding space and 4× cheaper to attend over.
Text path: tokenization and embedding lookup
The Nemotron processor produces two tensors: input_ids and attention_mask, both of shape (B, S).
- For image+text requests, the first ~256 positions hold
img_context_token_id(one per vision token).attention_maskis1for those corresponding visual-token positions. - For text-only requests, there are no image placeholders; you only have text tokens followed by padding.
attention_maskis0on padded positions, and those positions are ignored during inference.
The text-token embedding is pulled from Llama's input embedding table, yielding input_embeds of shape (B, S, 2048). Here, S is the sequence length. For example, when S=1024, the first ~256 token positions can be reserved for img_context_token_id, and the remaining ~768 positions are used for text plus padding.
Fusion
At this point there are two tensors: input_embeds (B, S, 2048) where the 256 image-placeholder rows are still meaningless, and vision_embeds (B, 256, 2048) from the ViT. Fusion is a single masked_scatter: wherever input_ids == img_context_token_id, overwrite that row in input_embeds with the corresponding row from vision_embeds. One operation, in-place, GPU-friendly. After this, input_embeds is the fused multimodal embedding the LM will consume.
Llama forward pass
The 16-layer Llama-3.2-1B transformer runs on the fused embeddings. This is the bulk of the FLOPs.
fused_embeds (B, S, 2048) ──► Llama (16 × [SDPA + SwiGLU]) ──► last_hidden_state (B, S, 2048)Pooling
The final step reduces (B, S, 2048) to (B, 2048) by picking the hidden state at the last non-padded position of each sequence:
attention_mask = [1, 1, 1, 1, 0, 0] → last_idx = 3
pooled = last_hidden_state[:, 3, :]It's implemented as a flip + argmax + gather so it traces cleanly to ONNX/TRT without data-dependent branches. The result is the 2048-dim embedding — ready to L2-normalize and store in a vector DB.
Serving the Model
Multimodal serving strategies differ in structure, and you may choose one over another depending on your use case.
Plan A — Single fused engine: --> Part 2
Package the whole pipeline (ViT → Embedding → Fusion → Llama → Pooling) into one ONNX/TRT artifact behind one Triton model. The client sends input_ids, attention_mask, and pixel_values; the engine returns the embedding.
The appeal is simplicity: one .plan, one config.pbtxt, standard dynamic batching, and nothing to coordinate. The catch is handling text-only requests. To handle both text-only and image+text traffic in one graph, you would need something like torch.cond to route subgraphs based on input conditions, and ONNX/TRT does not handle this gracefully. A graph that branches on image presence is painful to export, and TRT may reject it or fall back to a slow path. The workaround is to always run the ViT, even for text-only requests, by feeding dummy pixel_values. Dummy values are acceptable for text-only requests because the preprocessor outputs an attention_mask that deactivates image-token positions.
Additionally, the single-runtime strategy is fine if most traffic is multimodal; the ViT is the smaller of the two models, and you keep a clean static graph. If text-only traffic dominates, you end up paying GPU cycles for no useful work on many requests, and that is when a redesign makes sense.
| Pros | Cons |
|---|---|
| Simple ops story | Pays ViT cost on every request, even text-only |
| One engine to scale | No way to scale ViT and LM independently |
| Best for mostly-multimodal workloads | Entire model reloads on any config change |
One common question: why not run ViT and LM in parallel? The LM is data-dependent on the ViT — fusion needs vision_embeds before Llama can run. And both models are large enough to saturate the GPU at sane batch sizes, so there's no idle compute to fill. Parallelism doesn't buy anything here.
Plan B — Multi-engine + Python BLS router --> Part 3
Split the pipeline into independent TRT engines (embed, vit, lm, post) and orchestrate them with a thin Python Business Logic Scripting (BLS) model inside Triton. The router dispatches to embed always, fires vit only when the request includes an image, runs fusion on the GPU, then passes the result through lm and post. Intermediate tensors are handed between engines via DLPack so they stay GPU-resident — the only host-bound transfer is the final 2048-dim pooled output.
The advantage is that text-only requests genuinely skip the ViT — no zeroed dummy inputs, no wasted compute. Each engine can also be scaled independently; if your traffic mix justifies two lm instances and one vit, that's a config change. The cost is operational complexity: more .plan files to version and keep in sync, a Python hop in the hot path (small but nonzero), and multiple CUDA streams to coordinate on multimodal requests.
| Pros | Cons |
|---|---|
| Truly skips ViT for text-only | More configs, more .plan files |
| Each engine scales independently | Python in the hot path |
| Tensors stay GPU-resident via DLPack | Slightly higher per-request latency for image+text |
| Natural fit for mixed/text-heavy traffic |
Picking between them
If your workload is mostly multimodal and you want the simplest possible ops story, Plan A is the right call. If your traffic is mixed or text-heavy, or you need independent autoscaling per submodel, Plan B pays for itself. Small teams who want minimal surface area should default to Plan A and revisit only when profiling shows ViT waste.
Part 2 covers performance analysis for Plan A — Single fused engine across both text-only and text+image use cases, and Part 3 does the same for the more complex serving path, Plan B — Multi-engine + Python BLS router.